Summary of CNN
-
Types of layer in a Convolution Network
- Convolution
- Pooling
- F ully Connected
-
Convolution
How can computer detect edge in the picture?
Assume there are 6*6 picture and 3*3 filter.
Like below, we can get 4*4 vertical edge Matrix By convolution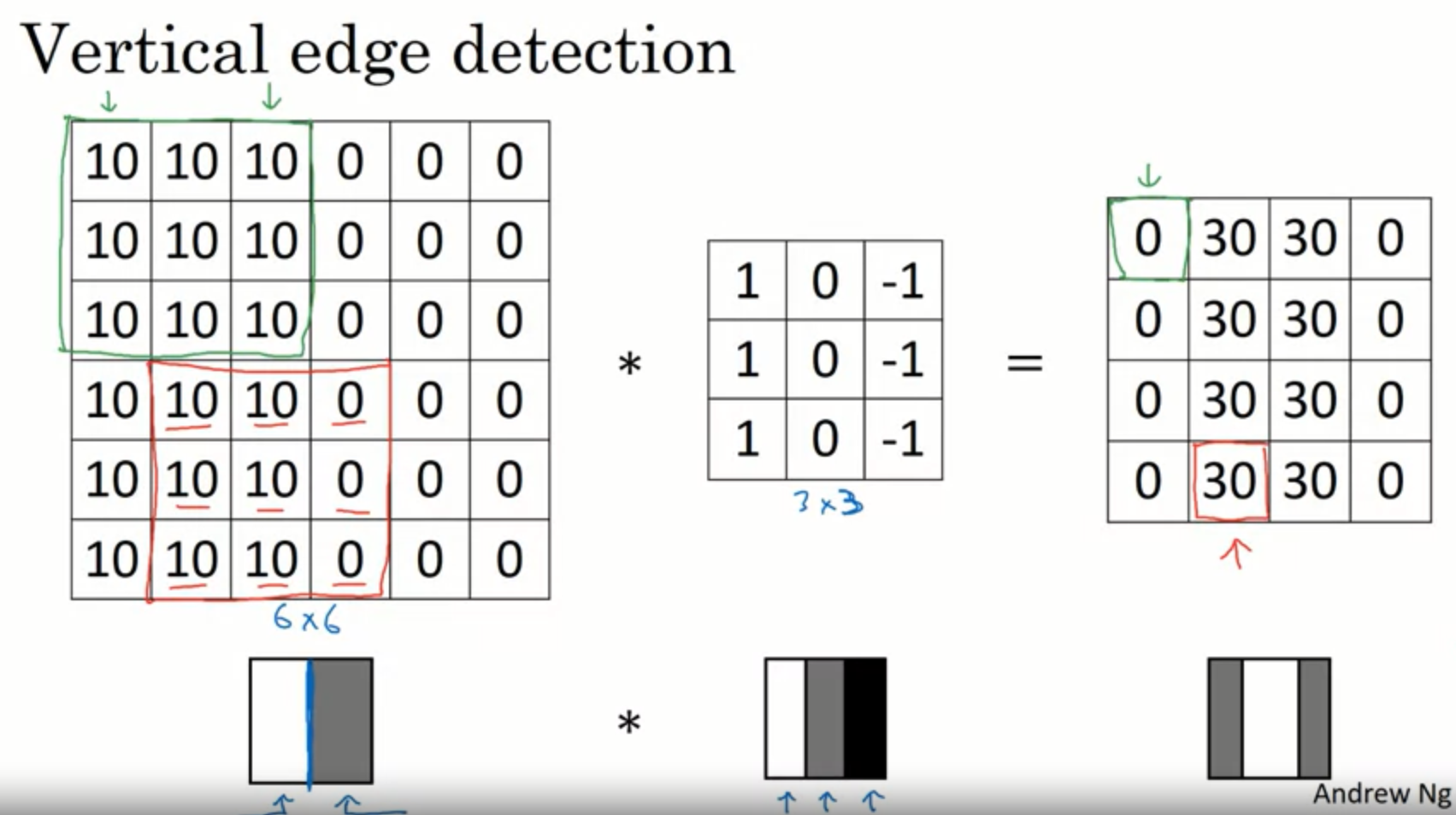
n x n Matrix * f x f Matrix = (n-f+1) x (n-f+1) Matrix
There are two disadvantages.
first is Image is getting smaller.
Second, We have to throw away about edge information. So We can add padding bytes.
(n+2p) x (n+2p) Matrix * f x f Matrix = (n+2p-f+1) x (n+2p-f+1) Matrix (p is padding size)
If stride > 1,
-
About 3D
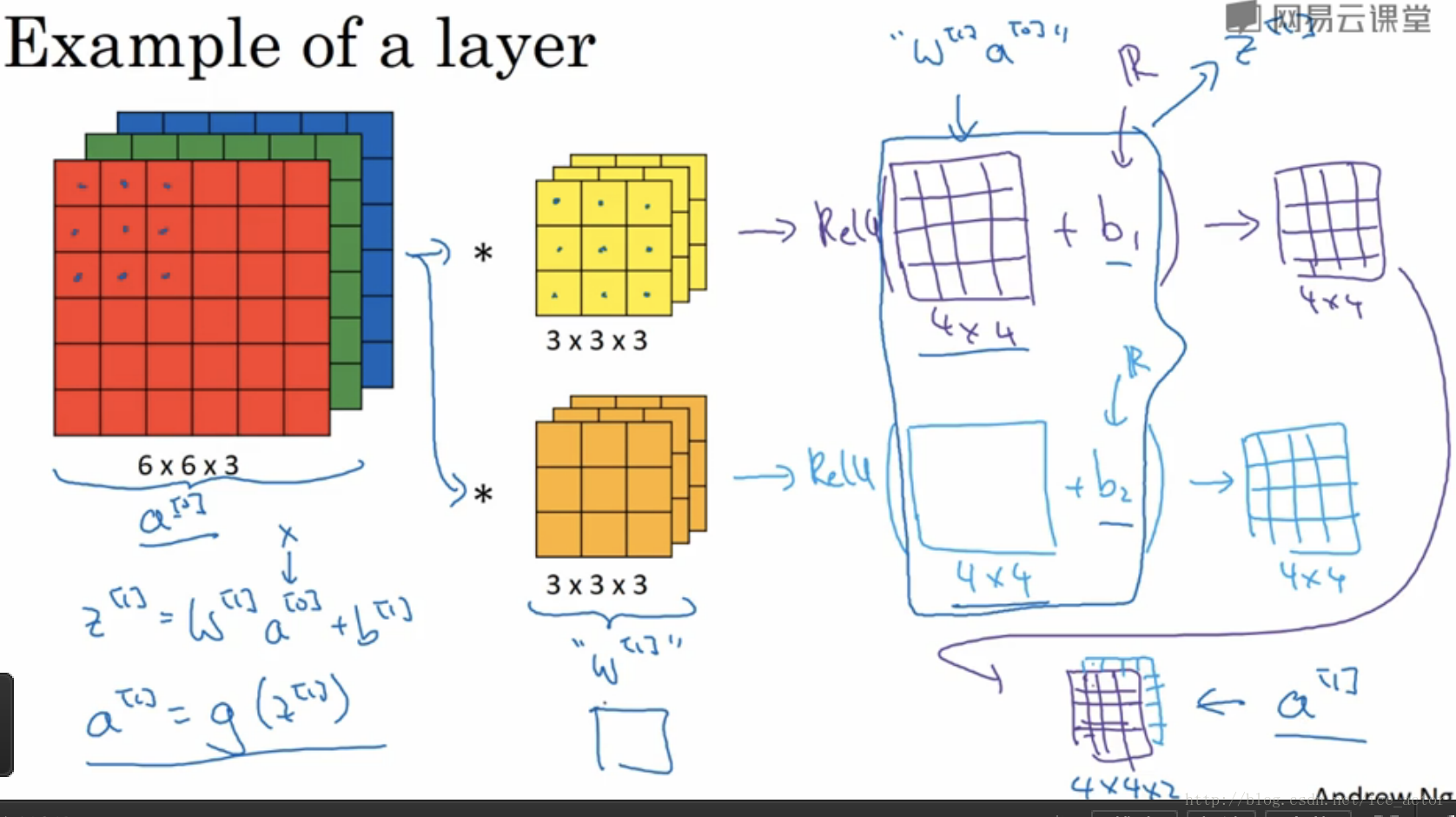
Like below, RGB is expressed 3 channels

And then, We do the convolution with 3 x 3 filter. If there ara many filters, We can get 4 x 4 x n ouput. It became a input in new Layer. And That is Convolution Neural Network
-
Pooling
For example Max pooling, Instead of calculation, We choose max value in each filter. If there are many channels, Output also has many channels. These is independent.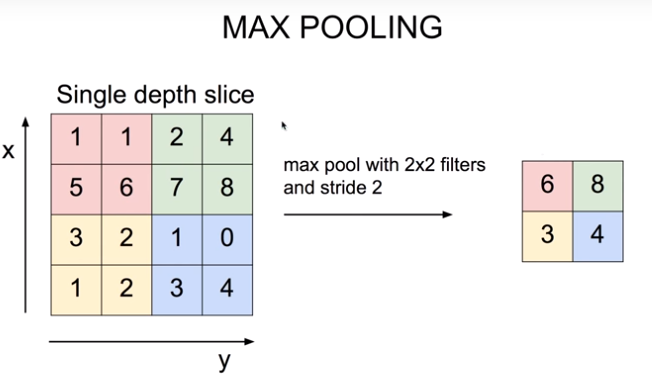
-
Fully Connected
Through Fully Connected Layer n X n X 3 Layer is strected to n^2 x 1 -
Architecture of CNN
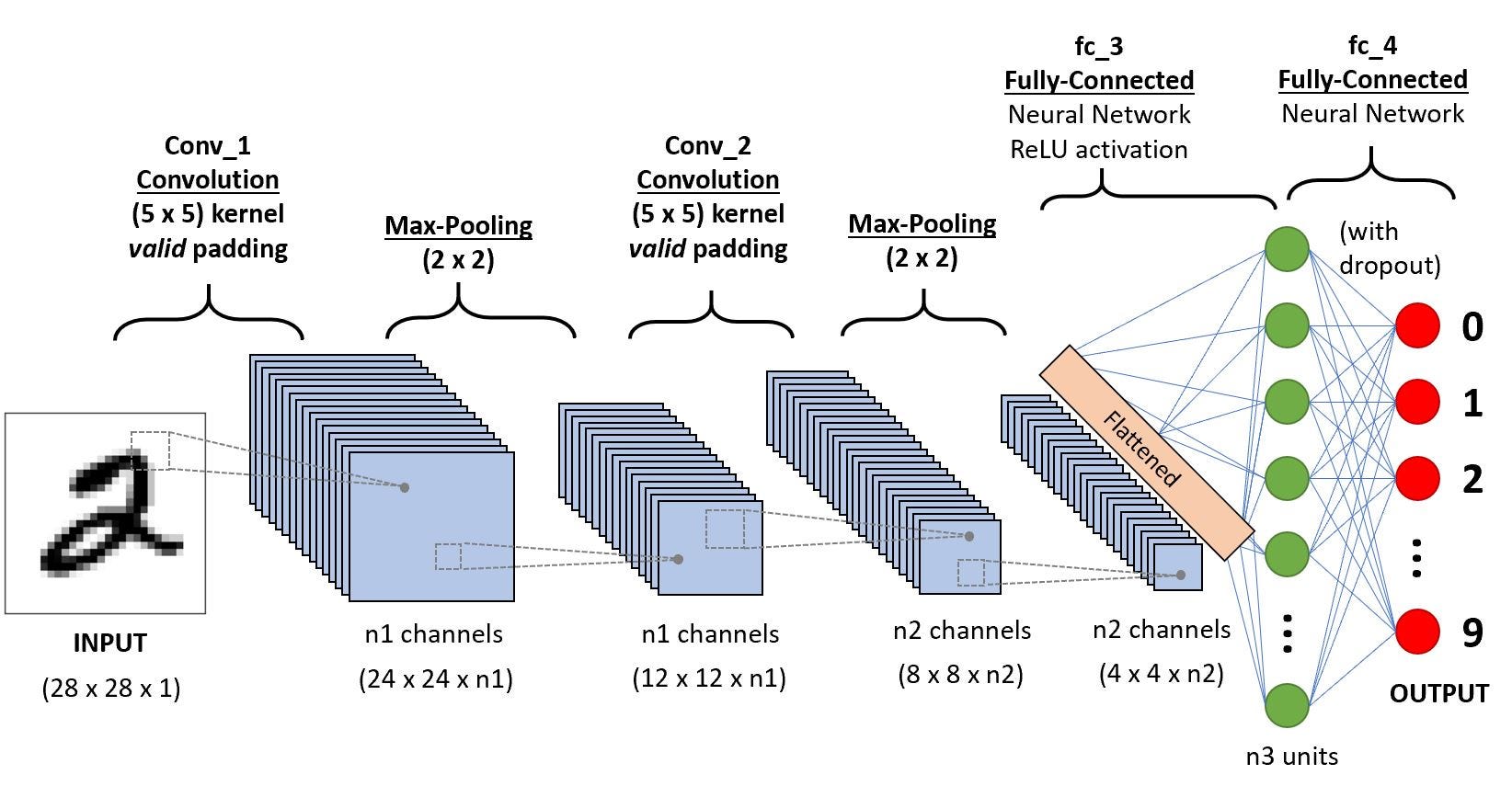
-
LeNet-5

As we can see, LeNet-5 Layer use average pooling and Fully Connected Layer twice. And then, Through Softmax 10 output. -
AlexNet
AlexNet is the first paper to make deep learning for computer vision a craze. AlexNet input start with 227 x 227 x 3 image. And use 11 x 11 filter, stride is 4. And use 3 x 3 max pooling. After use same convolution, max pooling. Finally we can get 6 x 6 x 256 (9216 Node) Matrix ANd use Fully Connected Layer, Softmax. AlexNet has 60M parameters.

-
VGG-16
Although VGG-16 has lots of hyper parameters, It use more simple network.

Classic Networks
-
Object Localization
Before we do Object Detectin, We have to do Object Localization, We have to classificate with localization in image
How can we find the location the car in the image? To do that, We can change our neural network to have a few more ouput units that ouput a bounding box. Object in image is expressed y = [ pc(if 1 is object), bx, by, bh, bw, class1, class2, ...]
In this, Neural Network can make output bx, by in primary position. It is called Landmark. For example, lx1,ly1 point left eye of top position and lx2, ly2 point bottom position. Distance of these landmark can detect eye closures.
Sliding windows detection
We can use small window like red rectangle. Window is moving top left to bottom right. If window detect something, It will make ouput through neural network. However, Sliding window detection has large disadvantage, which is the computational cost. It can be better using convolutional implementation. Nevertheless It can't detect accurate bounding box. A good way to get this ouput more accurate bounding boxes is with the YOLO algorithm. -
YOLO Algorithm

Instead of Sliding window, place down a grid on image. In example, Image is sliced 9 grid. A grid what has object will make output y. We can figure out where object is located. What we have to focus on, We're not implementing this algorithm 9 times. Instead, This is one single convolutional implantation. So this is a pretty efficient algorithm.